We introduce the One-shot Pruning Technique for Interchangeable Networks (OPTIN)
framework as a tool to increase the efficiency of pre-trained transformer architectures, across many domains, without requiring re-training. Recent works have explored improving transformer
efficiency, however often incur computationally expensive re-training procedures or depend on architecture-specific characteristics, thus impeding practical wide-scale adoption across multiple
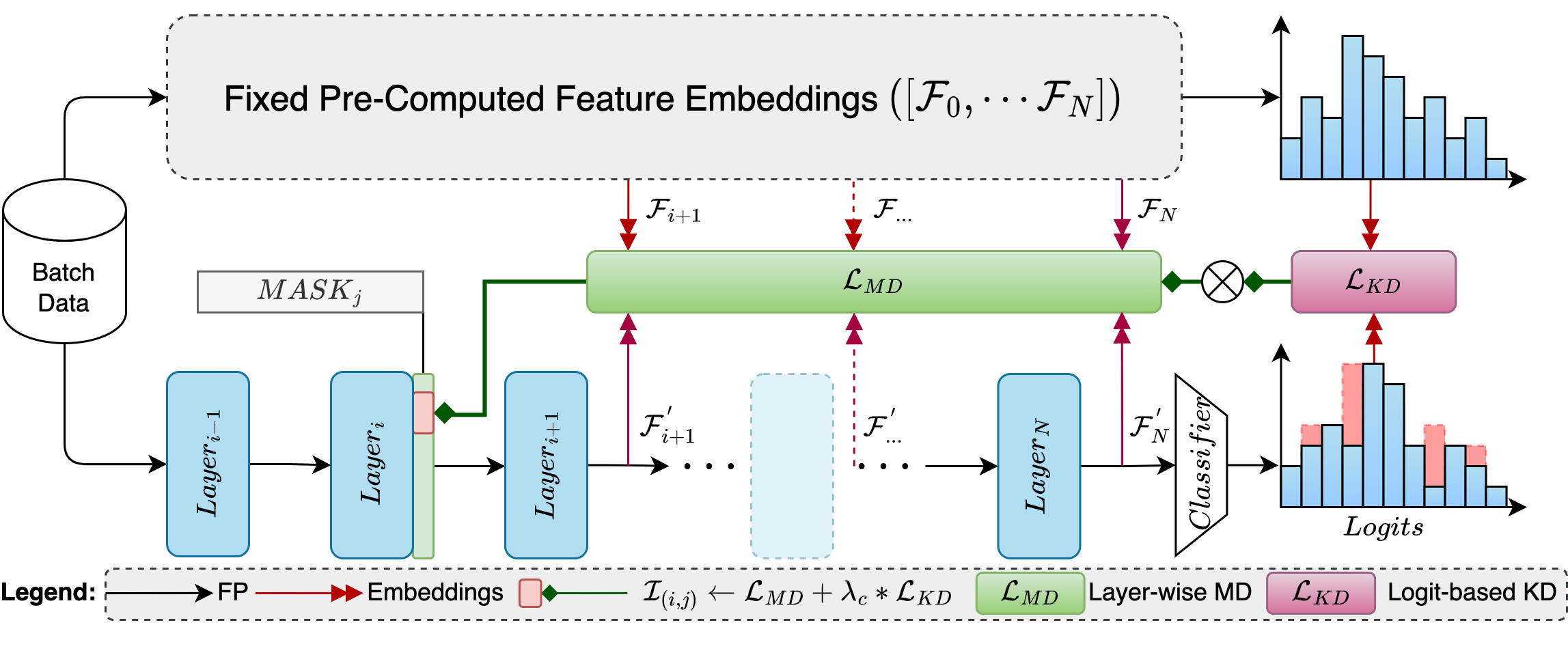
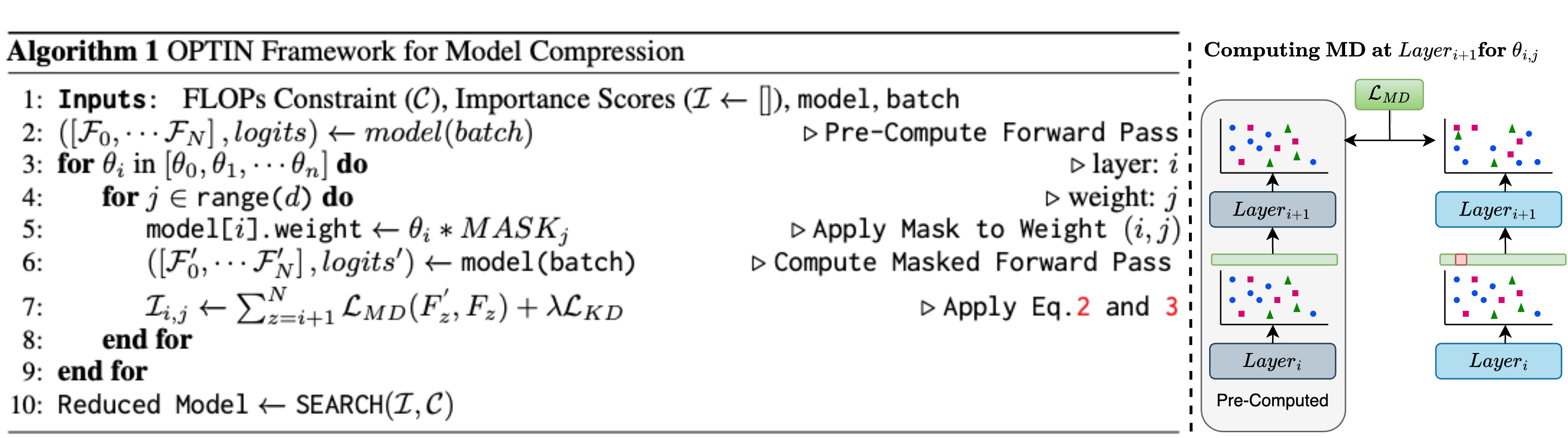
modalities. To address these shortcomings, the OPTIN framework leverages intermediate feature distillation, capturing the long-range dependencies of model parameters (coined trajectory),
to produce state-of-the-art results on natural language, image classification, transfer learning, and semantic segmentation tasks. Our motivation stems from the need for a generalizable model
compression framework that scales well across different transformer architectures and applications. Given a FLOP constraint, the OPTIN framework will compress the network while maintaining competitive
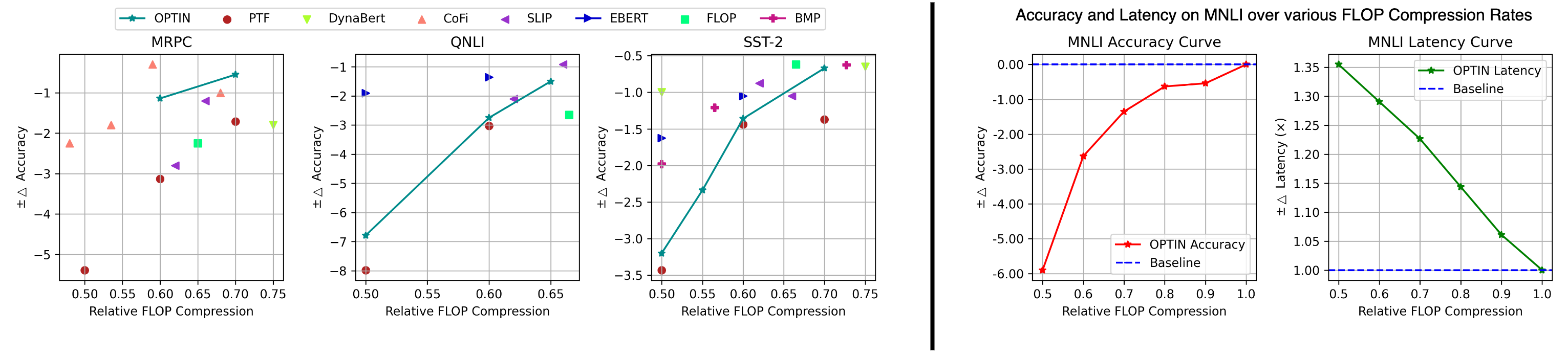
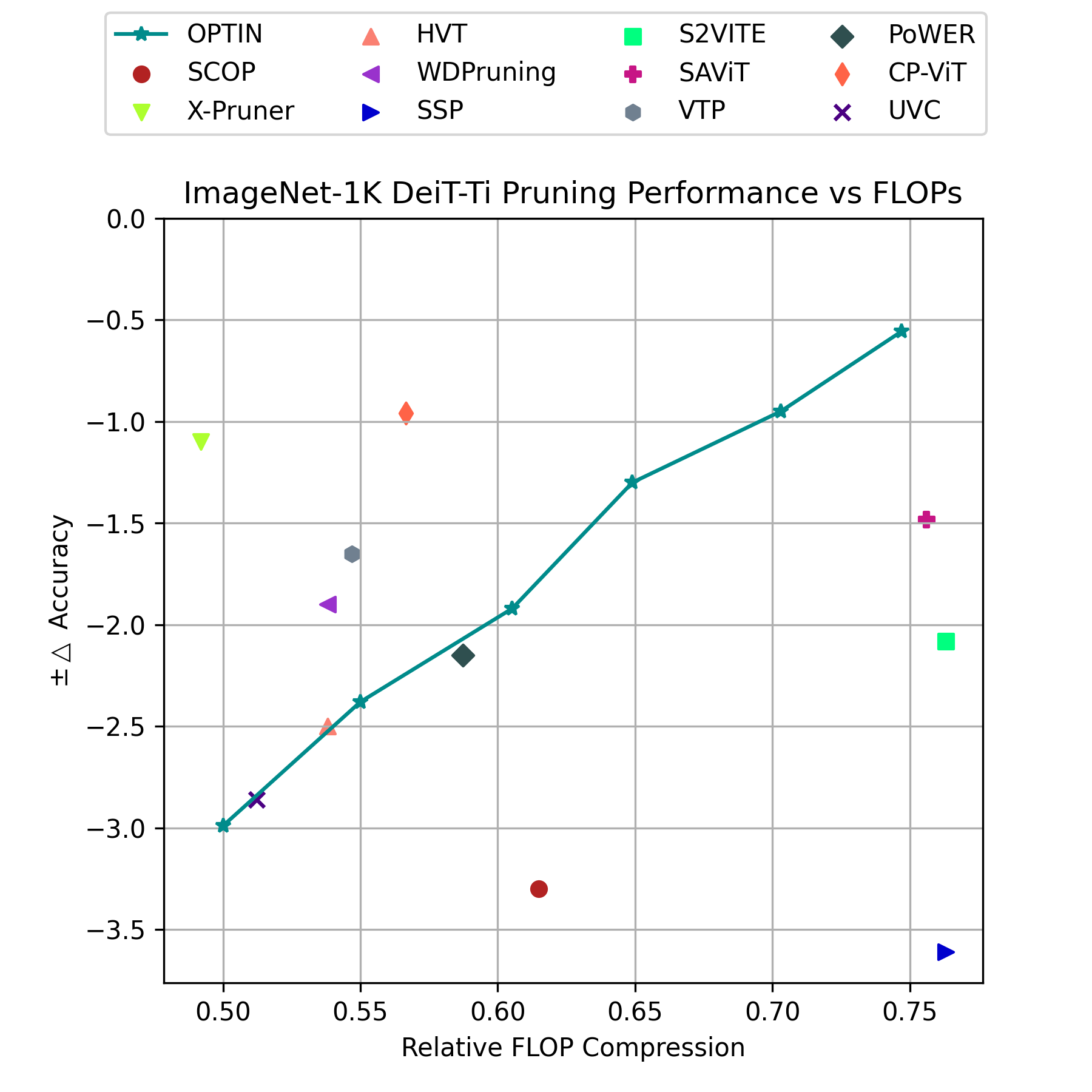
accuracy performance and improved throughput. Particularly, we show a ≤ 2% accuracy degradation from NLP baselines and a 0.5% improvement from state-of-the-art methods on image classification at competitive
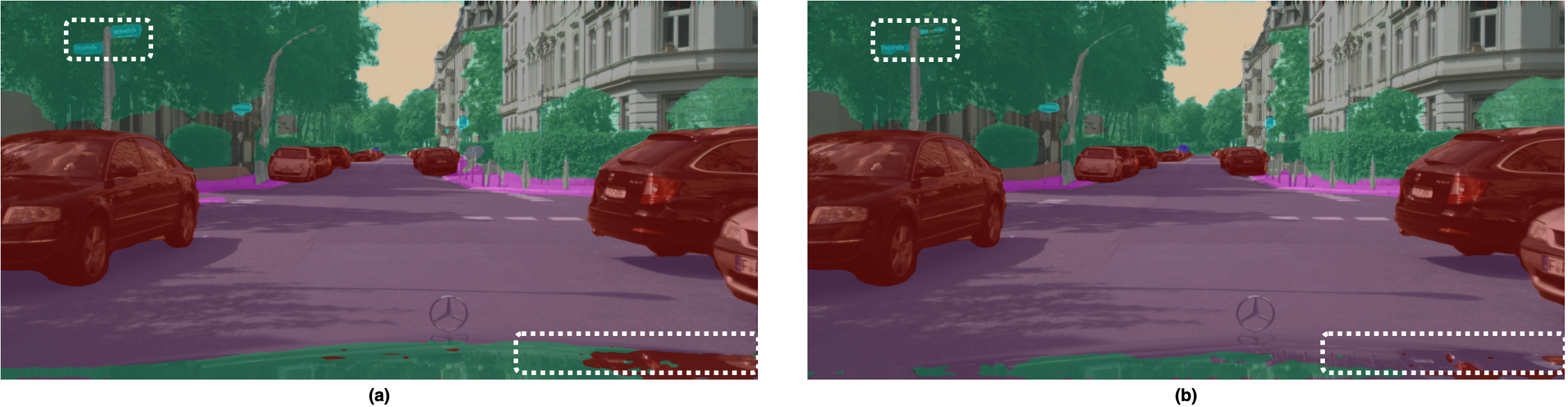
FLOPs reductions. We further demonstrate the generalization of tasks and architecture with comparative performance on Mask2Former for semantic segmentation and cnn-style networks. OPTIN presents one
of the first one-shot efficient frameworks for compressing transformer architectures that generalizes well across multiple class domains, in particular: natural language and image-related tasks,
without re-training.